1. 概述
在本文中,我们将比较BitSet和boolean[] 在不同场景下的性能。
我们通常非常宽松地使用术语性能,并考虑不同的含义。因此,我们将从了解术语“性能”的各种定义开始。
然后,我们将使用两种不同的性能指标进行基准测试:内存占用和吞吐量。为了对吞吐量进行基准测试,我们将比较位向量上的一些常见操作。
2. 绩效定义
性能是一个非常笼统的术语,指的是范围广泛的“性能”相关概念!
有时我们用这个术语来谈论特定应用程序的启动速度;也就是说,应用程序在能够响应其第一个请求之前所花费的时间。
除了启动速度,我们在谈性能的时候可能会想到内存占用。所以内存占用是这个术语的另一个方面。
可以将“性能”解释为我们的代码运行的“速度”。所以延迟是另一个性能方面。
对于某些应用程序,了解每秒操作数方面的系统容量非常重要。所以吞吐量可以是性能的另一个方面。
有些应用程序只有在响应一些请求并从技术上“预热”之后,才能以最佳性能水平运行。因此,达到峰值性能的时间是另一个方面。
可能的定义列表还在继续!然而,在整篇文章中,我们将只关注两个性能指标:内存占用和吞吐量。
3.内存占用
虽然我们可能期望 布尔值 只消耗一位,但boolean[] 中的 每个 布尔 值都消耗一个字节的内存。这主要是为了避免单词撕裂和可访问性问题。因此,如果我们需要一个位向量, boolean[] 将占用大量内存。
为了使事情更具体,我们可以使用Java 对象布局 (JOL)来检查 boolean[] 的内存布局,比如包含 10,000 个元素:
boolean[] ba = new boolean[10_000];
System.out.println(ClassLayout.parseInstance(ba).toPrintable());
这将打印内存布局:
[Z object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (1)
4 4 (object header) 00 00 00 00 (0)
8 4 (object header) 05 00 00 f8 (-134217723)
12 4 (object header) 10 27 00 00 (10000)
16 10000 boolean [Z. N/A
Instance size: 10016 bytes
如上所示,此 boolean[] 消耗大约 10 KB 的内存。
另一方面,BitSet 使用原始数据类型(特别是long)和按位操作的组合来实现每个标志足迹一位。因此 ,与具有相同大小的boolean[] 相比,具有 10,000 位 的BitSet 消耗的内存要少得多:
BitSet bitSet = new BitSet(10_000);
System.out.println(GraphLayout.parseInstance(bitSet).toPrintable());
同样,这将打印 BitSet的内存布局:
java.util.BitSet@5679c6c6d object externals:
ADDRESS SIZE TYPE PATH
76beb8190 24 java.util.BitSet
76beb81a8 1272 [J .words
正如预期的那样,具有相同位数的 BitSet 消耗大约 1 KB,这远小于 boolean[]。
我们还可以比较不同位数的内存占用:
Path path = Paths.get("footprint.csv");
try (BufferedWriter stream = Files.newBufferedWriter(path, StandardOpenOption.CREATE)) {
stream.write("bits,bool,bitsetn");
for (int i = 0; i <= 10_000_000; i += 500) {
System.out.println("Number of bits => " + i);
boolean[] ba = new boolean[i];
BitSet bitSet = new BitSet(i);
long baSize = ClassLayout.parseInstance(ba).instanceSize();
long bitSetSize = GraphLayout.parseInstance(bitSet).totalSize();
stream.write((i + "," + baSize + "," + bitSetSize + "n"));
if (i % 10_000 == 0) {
stream.flush();
}
}
}
上面的代码将计算具有不同长度的两种类型的位向量的对象大小。然后它将大小比较写入 CSV 文件并将其刷新。
现在,如果我们绘制此 CSV 文件,我们将看到 内存占用的绝对差异随着位数的增加而增加:
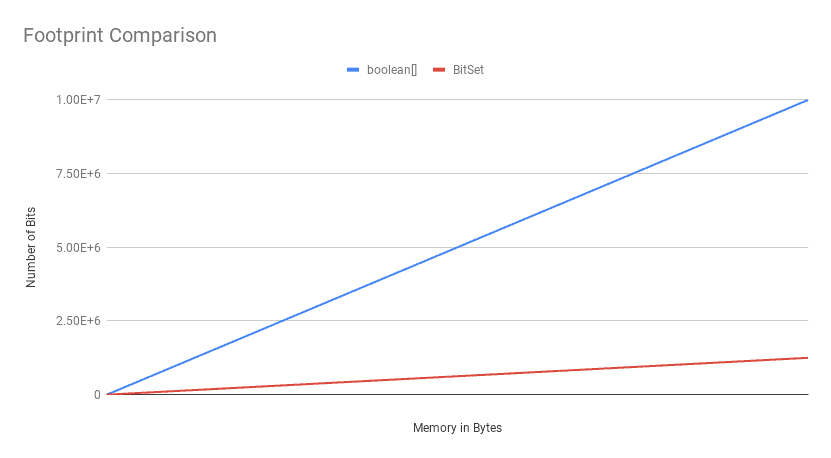
这里的关键是, BitSet 在内存占用方面优于 boolean[] ,除了最少的位数。
4.吞吐量
为了比较 BitSet 和 boolean[] 的吞吐量,我们将基于三种不同但日常的位向量操作进行三个基准测试:
- 获取特定位的值
- 设置或清除特定位的值
- 计算设置位的数量
这是我们将用于比较不同长度的位向量的吞吐量的常见设置:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.Throughput)
public class VectorOfBitsBenchmark {
private boolean[] array;
private BitSet bitSet;
@Param({"100", "1000", "5000", "50000", "100000", "1000000", "2000000", "3000000",
"5000000", "7000000", "10000000", "20000000", "30000000", "50000000", "70000000", "1000000000"})
public int size;
@Setup(Level.Trial)
public void setUp() {
array = new boolean[size];
for (int i = 0; i < array.length; i++) {
array[i] = ThreadLocalRandom.current().nextBoolean();
}
bitSet = new BitSet(size);
for (int i = 0; i < size; i++) {
bitSet.set(i, ThreadLocalRandom.current().nextBoolean());
}
}
// omitted benchmarks
}
如上所示,我们正在创建 长度在 100-1,000,000,000 范围内的boolean[] s 和 BitSet s。此外,在设置过程中设置了一些位之后,我们将对 boolean[] 和 BitSet执行不同的操作。
4.1. 得到一点
乍一看, boolean[] 中的直接内存访问似乎比在BitSet中每次get执行两次按位操作 (左移加一个与 操作)更有效。 另一方面, BitSet的内存紧凑性可能允许它们在高速缓存行中容纳更多值。
让我们看看谁赢了!以下是 JMH每次将使用不同的 大小 状态值运行的基准测试:
@Benchmark
public boolean getBoolArray() {
return array[ThreadLocalRandom.current().nextInt(size)];
}
@Benchmark
public boolean getBitSet() {
return bitSet.get(ThreadLocalRandom.current().nextInt(size));
}
4.2. 获得一点:吞吐量
我们将使用以下命令运行基准测试:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff get.csv getBitSet getBoolArray
这将使用四个线程和两个分支运行与 get 相关的基准测试,使用 Linux 上的 perf 工具分析它们的执行统计信息,并将结果输出到bench-get.csv文件中。“ -prof perfnorm” 将使用 Linux 上的 perf工具对基准进行分析,并根据操作数对性能计数器进行标准化。
由于命令结果非常冗长,我们将只在此处绘制它们。在此之前,让我们看看每个基准测试结果的基本结构:
"Benchmark","Mode","Threads","Samples","Score","Score Error (99.9%)","Unit","Param: size"
"getBitSet","thrpt",4,40,184790139.562014,2667066.521846,"ops/s",100
"getBitSet:L1-dcache-load-misses","thrpt",4,2,0.002467,NaN,"#/op",100
"getBitSet:L1-dcache-loads","thrpt",4,2,19.050243,NaN,"#/op",100
"getBitSet:L1-dcache-stores","thrpt",4,2,6.042285,NaN,"#/op",100
"getBitSet:L1-icache-load-misses","thrpt",4,2,0.002206,NaN,"#/op",100
"getBitSet:branch-misses","thrpt",4,2,0.000451,NaN,"#/op",100
"getBitSet:branches","thrpt",4,2,12.985709,NaN,"#/op",100
"getBitSet:dTLB-load-misses","thrpt",4,2,0.000194,NaN,"#/op",100
"getBitSet:dTLB-loads","thrpt",4,2,19.132320,NaN,"#/op",100
"getBitSet:dTLB-store-misses","thrpt",4,2,0.000034,NaN,"#/op",100
"getBitSet:dTLB-stores","thrpt",4,2,6.035930,NaN,"#/op",100
"getBitSet:iTLB-load-misses","thrpt",4,2,0.000246,NaN,"#/op",100
"getBitSet:iTLB-loads","thrpt",4,2,0.000417,NaN,"#/op",100
"getBitSet:instructions","thrpt",4,2,90.781944,NaN,"#/op",100
如上所示,结果是一个以逗号分隔的字段列表,每个字段代表一个指标。例如, “thrpt” 表示吞吐量, “L1-dcache-load-misses” 是一级数据缓存的缓存未命中数, “L1-icache-load-misses” 是该级别的缓存未命中数1 个指令缓存, “instructions” 表示每个基准测试的 CPU 指令数。另外,最后一个字段代表位数,第一个字段代表基准方法名称。
这是具有 4 核 Intel(R) Xeon(R) CPU 2.20GHz 的典型 Digitial Ocean droplet 的吞吐量基准测试结果:
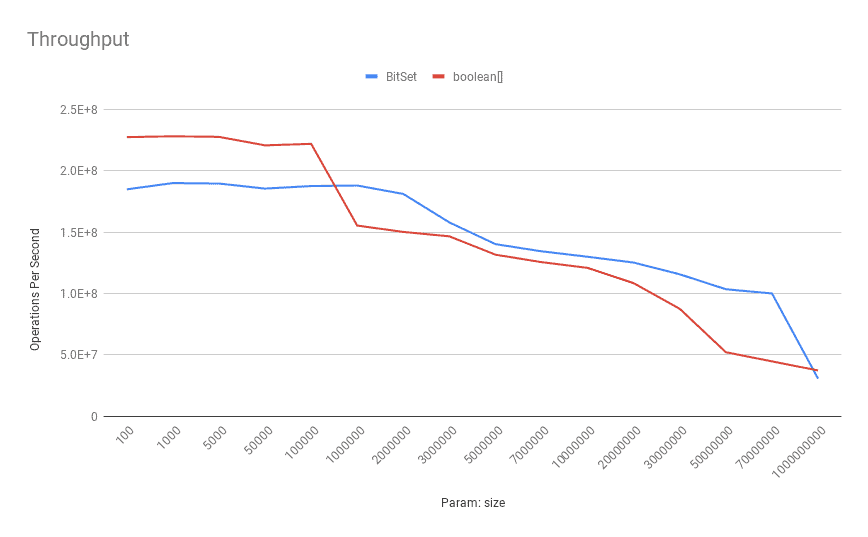
如上所示,boolean [] 在较小的尺寸上具有更好的吞吐量。当位数增加时, BitSet 在吞吐量方面优于 boolean[] 。更具体地说,在 100,000 位之后,BitSet 表现出优越的性能。
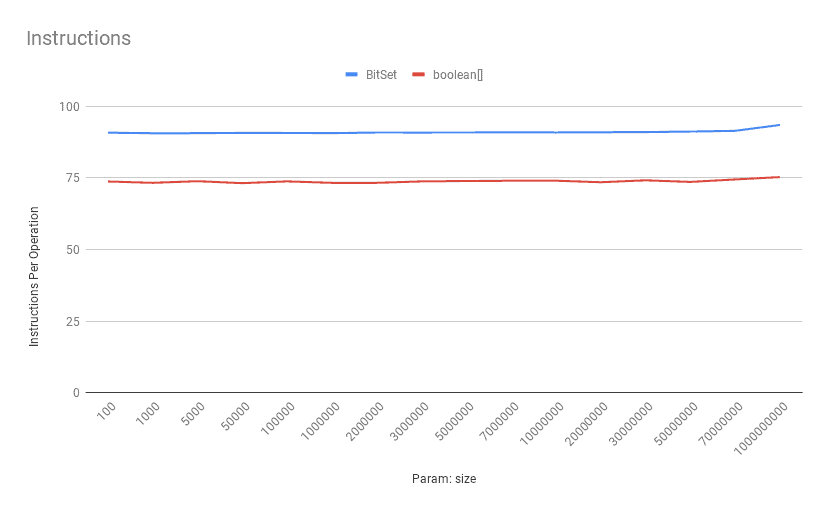
4.3. 获得一点:每个操作的指令
正如我们所料,boolean[] 上的 get 操作 每次操作的指令更少:
4.4. 了解一点:数据缓存未命中
现在,让我们看看数据缓存未命中是如何寻找这些位向量的:
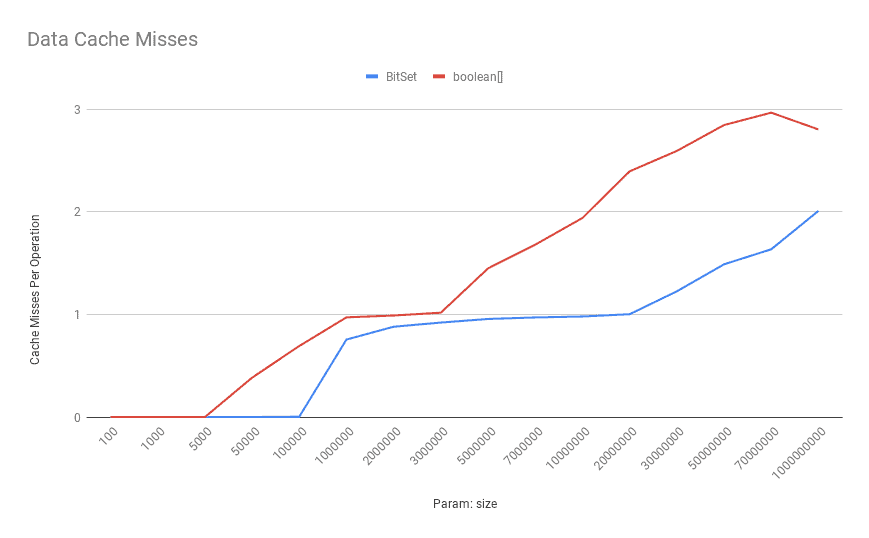
如上所示,boolean[]的数据缓存未命中 数随着位数的增加而增加。
所以缓存未命中比在这里执行更多指令的代价要高得多。因此, 在这种情况下, BitSet API 在大多数情况下都优于boolean[] 。
4.5. 设定一点
为了比较集合操作的吞吐量,我们将使用这些基准:
@Benchmark
public void setBoolArray() {
int index = ThreadLocalRandom.current().nextInt(size);
array[index] = true;
}
@Benchmark
public void setBitSet() {
int index = ThreadLocalRandom.current().nextInt(size);
bitSet.set(index);
}
基本上,我们选择一个随机位索引并将其设置为 true。同样,我们可以使用以下命令运行这些基准测试:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff set.csv setBitSet setBoolArray
让我们看看这些操作在吞吐量方面的基准测试结果如何:
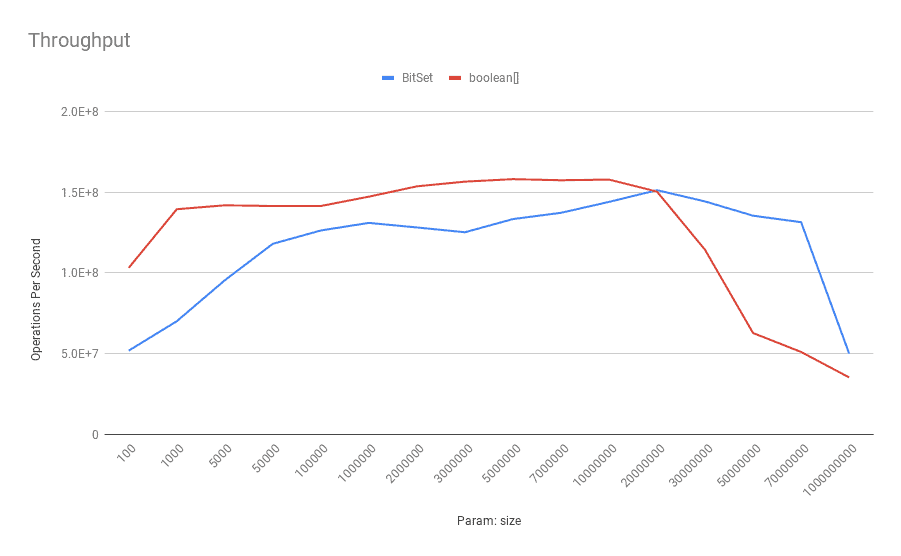
这次 boolean[] 在大多数情况下都优于 BitSet ,除了非常大的尺寸。由于我们可以 在高速缓存行中拥有更多的BitSet 位,因此高速缓存未命中和错误共享的影响在BitSet 实例中可能更加显着 。
这是数据缓存未命中比较:
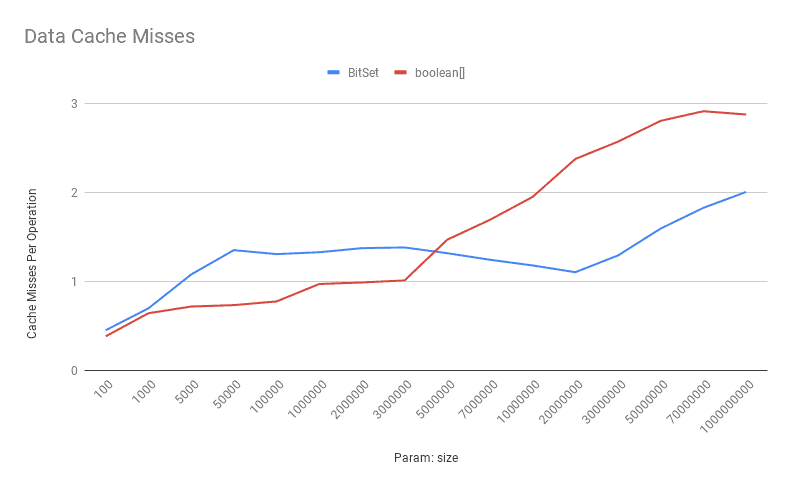
如上所示, boolean[] 的数据缓存未命中对于低到中等数量的位来说非常低。同样,当位数增加时, boolean[] 会遇到更多缓存未命中。
类似地, boolean[] 的每次操作的指令数 比 BitSet少:
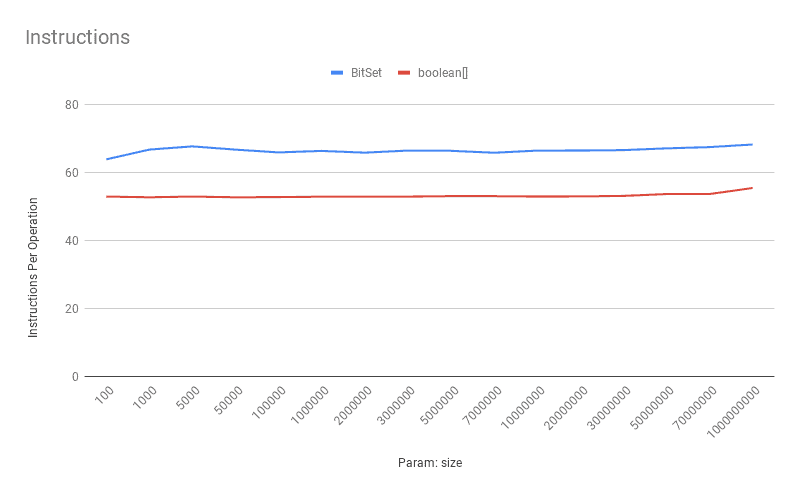
4.6. 基数
此类位向量中的其他常见操作之一是计算设置位的数量。这次我们将运行这些基准测试:
@Benchmark
public int cardinalityBoolArray() {
int sum = 0;
for (boolean b : array) {
if (b) sum++;
}
return sum;
}
@Benchmark
public int cardinalityBitSet() {
return bitSet.cardinality();
}
我们可以再次使用以下命令运行这些基准测试:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff cardinal.csv cardinalityBitSet cardinalityBoolArray
以下是这些基准测试的吞吐量:
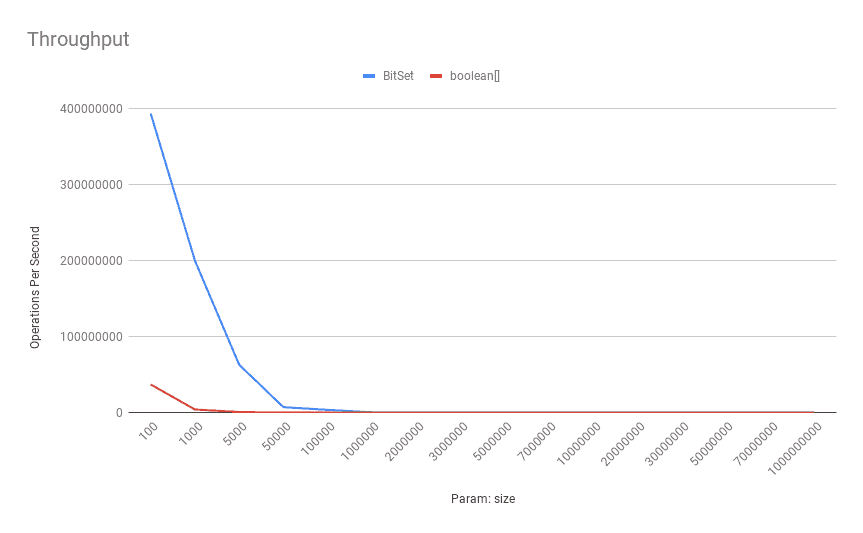
在基数吞吐量方面, BitSet API 几乎所有时间都优于boolean[] ,因为它的迭代次数少得多。更具体地说, BitSet 只需迭代其内部 的 long[] ,与相应的boolean[]相比,它的元素数量要少得多 。
此外,由于这条线和位向量中设置位的随机分布:
if (b) {
sum++;
}
分支预测错误的成本也可能是决定性的:
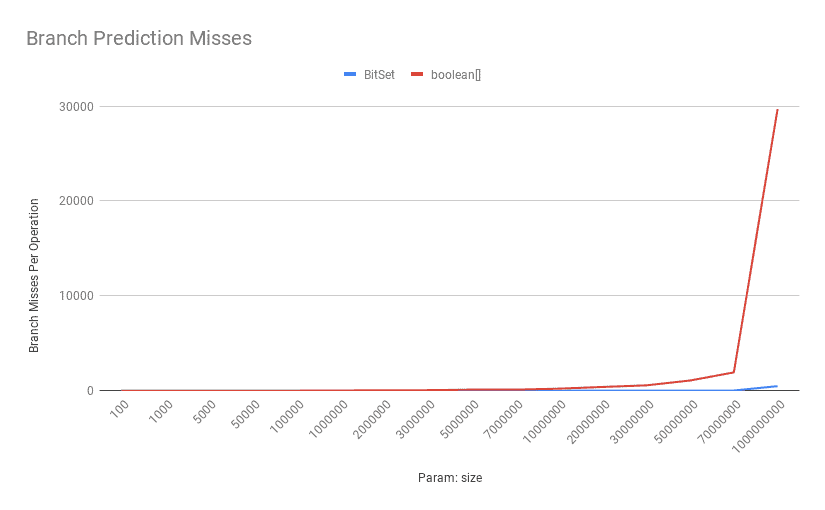
如上所示,随着位数的增加, boolean[] 的错误预测数量显着增加。
5.总结
在本文中,我们比较了 BitSet 和 boolean[] 在三种常见操作方面的吞吐量:获取位、设置位和计算基数。除了吞吐量之外,我们还看到 与具有相同大小的boolean[]相比, BitSet 使用的内存要少得多。
回顾一下,在单比特读取密集型场景中, boolean[]在更小的尺寸下 优于 BitSet 。但是,当位数增加时, BitSet 具有更高的吞吐量。
此外,在单比特写入繁重的场景中, boolean[] 几乎所有时间都表现出卓越的吞吐量,除了非常多的比特。另外,在批量读取场景中, BitSet API 完全支配了 boolean[] 方法。
我们使用 JMH-perf 集成来捕获低级 CPU 指标,例如 L1 数据缓存未命中或未命中分支预测。从 Linux 2.6.31 开始,perf是标准的 Linux 分析器,能够公开有用的性能监控计数器或PMC。 也可以单独使用此工具。要查看此独立用法的一些示例,强烈建议阅读Branden Greg的博客。
像往常一样,所有示例都可以在 GitHub 上找到。此外,所有执行基准测试的 CSV 结果也可在 GitHub 上访问。
与往常一样,本教程的完整源代码可在GitHub上获得。
Post Directory
